前面了解过纯js实现了录音功能,并也自学了一些关于前端二进制的内容,现在终于可以利用阿里云来实现下智能语音识别的功能了。
一、准备
首先,先登录阿里云官网查看下官方文档(一句话识别),提供了java,c++,ios等,可惜我只会些node啊,所以直接看下restful api,毕竟node也是可以发送http请求的嘛。
功能介绍中阐明了产品的功能,也说明了使用的一些条件,比如POST方式、不超过一分钟,当然重要的还是音频编码格式和音频采样率的限制。这儿我使用PCM格式,和16k的音频采样率。
回看我前面用js实现的录音文件,我们只需要使用他的encodePCM()接口就行了。
二、直接传递二进制
前端部分
html与js
简单的用两个按钮实现开始录音和结束录音,第三个按钮实现上传到服务器翻译的功能,最后页面上设置个div存放翻译的内容。
<input type="button" value="开启" onClick="startRecord()" /> <input type="button" value="停止" onClick="endRecord()" /> <input type="button" value="上传翻译" onClick="transRecord()" /> <div id="Box"></div>
js部分的话,引入recorder.js文件(在纯js实现录音与播放里有)。全局定义了两个变量,一个是对div的引用和录音对象的引用。
var oDiv = document.getElementById('Box'),recoder = null;首先看下开始录音的函数,
function startRecord() {
if (!recorder) {
recorder = new Recorder({
sampleRate: 16000 // 阿里云要求16000的采样率
});
}
recorder.start();
}停止比较简单,只需要调用对应的stop()接口就行了,
function endRecord (e) {
recorder && recoder.stop();
}将得到的blob数据放在formdata中,以post的方式发送给后端,content-type得设置成multipart/form-data。
function transRecord (e) {
let pcm = recorder.getPCMBlob(),formdata = new FormData();
formdata.append('file',pcm);
fetch('/speech',{
method: 'POST',credentials: 'include',headers: {
'Content-Type': 'multipart/form-data'
},body: formdata
}).then(function(response) {
console.log(response);
});
}后端node部分
简单模拟下后端的处理,此处用到了@alicloud/pop-core和request依赖。
先引入需要使用的全局变量,
var http = require('http'),fs = require('fs'),ROAClient = require('@alicloud/pop-core').ROAClient,request = require('request');
http.createServer(function(req,res) {
// .... do something
}).listen(8080);监听好8080端口后,我们开始后台的逻辑吧,首先先处理下默认的index页面和recorder.js的加载问题,首先是处理index.html的请求:
if (req.url == '/' && req.method.toLowerCase() == 'get') {
res.writeHead(200,{'content-type': 'text/html'});
fs.readFile('index.html',function(err,data){
if (err) {
console.log('error');
} else {
res.end(data);
}
});
}然后是recorder.js文件的处理,和html相同,
if (req.url == '/recorder.js' && req.method.toLowerCase() ==' get') {
res.writeHead(200,{'content-type':'text/html'});
fs.readFile('recorder.js',data){
if (err) {
console.log('error');
} else {
res.end(data);
}
});
}静态页面都处理好了,下面要去处理语音请求了,
if (req.url == '/speech' && req.method.toLowerCase() == 'post') {
// 缓存二进制数据
var data = [];
req.on('data',function(chunk) {
data.push(chunk);
}).on('end',function() {
var buffer = Buffer.concat(data);
// .... 继续去处理二进制数据
});
}此时,data中就保存了前端传来的二进制数据,只要将这个数据发送到阿里服务器上识别就行了。
token获取
由于官方文档上说到http请求头中的X-NLS-Token值是要额外去获取的,所以,先请求实现获取token令牌。
获取访问令牌中,直接看下node版的demo,是需要安装个@alicloud/pop-core依赖的,所以先用npm装好。再将其demo拷贝出来,由于请求需要access-key-id和access-key-secret,所以我们再去创建下应用。创建应用的话,官方操作手册可以查看:管理项目。将创建好的access-key-id和access-key-secret填入到对应的字段内。这个token是带超时的,应该有更好的保管方式而不是每次都是去请求。
var client = new ROAClient({
accessKeyId:'LTAIeUTLr12sCAgM',accessKeySecret:'bHgMr4oLJjegKswB8Usy72zh87HHJI',endpoint:'http://nls-Meta.cn-shanghai.aliyuncs.com',apiVersion:'2018-05-18'
});
client.request('POST','/pop/2018-05-18/tokens').then((result) => {
console.log('tokenId',result.Token.Id);
// 获取到token后再去发送录音数据
// ....
});录音数据识别
还差最后一步发送录音文件到阿里就可以识别录音文件啦。查看官方文档,文档非常详细,我们需要设置3个(appkey、format、sample_rate)必选参数,并且http头中也要设置4个必填的参数。
组装好options等待赋值token值,
const options = {
url: 'http://nls-gateway.cn-shanghai.aliyuncs.com/stream/v1/asr?appkey=UL9Xm7wmBiTa2YmW&sample_rate=16000&format=pcm',method: 'POST',headers: {
'X-NLS-Token':'','Content-Type': 'application/octet-stream','Content-Length': dataBuffer.byteLength,'Host': 'nls-gateway.cn-shanghai.aliyuncs.com'
},body: dataBuffer
};修改刚才获取token的地方,将输入token的语句替换为:
options.headers['X-NLS-Token'] = result.Token.Id;
request(options,function(error,response,body) {
if (error) {
return console.error('upload Failed:',error);
}
console.log('Upload successful! Server responded with:',body);
// 将检测的结果发送给客户端
res.writeHead(200,{'Content-Type': 'application/json;charset=utf-8'});
res.end(body);
});这下就可以开始愉快地玩耍语音啦,后面有详细代码的地址。
三、转base64后发送
查询到二进制数据可以转成base64后,放在json中发送给后端。于是便尝试了一把。
前端部分
修改下transRecord函数,将blob转成base64格式,
function transRecord (e) {
let pcm = recoder.encodePCM();
blobToDataURL(pcm,function(base) {
fetch("/speech",{
method: "POST",headers: {
'Content-Type': 'application/json'
},body: JSON.stringify({
data: base
})
}).then(function(response) {
return response.json();
}).then(function(data) {
oDiv.innerText = data.data.result;
});
});
}
// blob转base64
function blobToDataURL(blob,callback) {
let a = new FileReader();
a.onload = function (e) {
callback(e.target.result);
}
a.readAsDataURL(blob);
}node部分
唯一不同地是接收数据,只需要将接受流文件地地方修改成取对象值地方式就行了,
var data = req.body,dataBuffer = newBuffer(data.data,'base64');
当然这么做还会遇到一个问题,当录音时间稍微长些时,就会出现413错误。
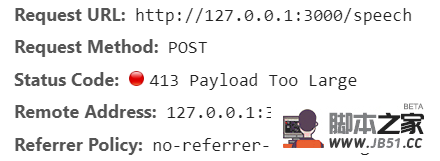
网上也是有处理的方式,当然并不推荐这么处理,毕竟好好的数据可以直接发送给后端,还得编码一次,再让后端解码一次,实在时浪费性能。这么处理下,只是为了证明二进制可以编码成base64的字符串,并以json的格式发送给后端。
整个实例的话,可以查看基于阿里云实现简单的语音识别功能(node)。
