前文我们了解了k8s上的NetworkPolicy资源的使用和工作逻辑,回顾请参考:https://www.cnblogs.com/qiuhom-1874/p/14227660.html;今天我们来聊一聊Pod调度策略相关话题;
在k8s上有一个非常重要的组件kube-scheduler,它主要作用是监听apiserver上的pod资源中的nodename字段是否为空,如果该字段为空就表示对应pod还没有被调度,此时kube-scheduler就会从k8s众多节点中,根据pod资源的定义相关属性,从众多节点中挑选一个最佳运行pod的节点,并把对应主机名称填充到对应pod的nodename字段,然后把pod定义资源存回apiserver;此时apiserver就会根据pod资源上的nodename字段中的主机名,通知对应节点上的kubelet组件来读取对应pod资源定义,kubelet从apiserver读取对应pod资源定义清单,根据资源清单中定义的属性,调用本地docker把对应pod运行起来;然后把pod状态反馈给apiserver,由apiserver把对应pod的状态信息存回etcd中;整个过程,kube-scheduler主要作用是调度pod,并把调度信息反馈给apiserver,那么问题来了,kube-scheduler它是怎么评判众多节点哪个节点最适合运行对应pod的呢?
在k8s上调度器的工作逻辑是根据调度算法来实现对应pod的调度的;不同的调度算法,调度结果也有所不同,其评判的标准也有所不同,当调度器发现apiserver上有未被调度的pod时,它会把k8s上所有节点信息,挨个套进对应的预选策略函数中进行筛选,把不符合运行pod的节点淘汰掉,我们把这个过程叫做调度器的预选阶段(Predicate);剩下符合运行pod的节点会进入下一个阶段优选(Priority),所谓优选是在这些符合运行pod的节点中根据各个优选函数的评分,最后把每个节点通过各个优选函数评分加起来,选择一个最高分,这个最高分对应的节点就是调度器最后调度结果,如果最高分有多个节点,此时调度器会从最高分相同的几个节点随机挑选一个节点当作最后运行pod的节点;我们把这个这个过程叫做pod选定过程(select);简单讲调度器的调度过程会通过三个阶段,第一阶段是预选阶段,此阶段主要是筛选不符合运行pod节点,并将这些节点淘汰掉;第二阶段是优选,此阶段是通过各个优选函数对节点评分,筛选出得分最高的节点;第三阶段是节点选定,此阶段是从多个高分节点中随机挑选一个作为最终运行pod的节点;大概过程如下图所示
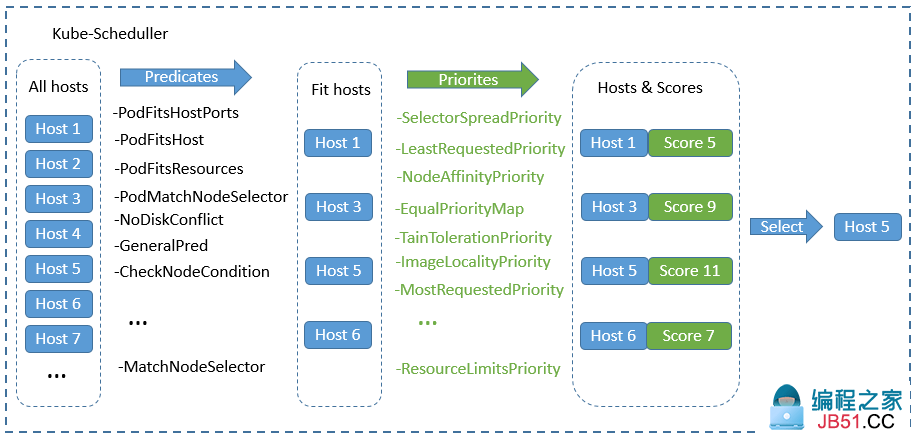
提示:预选过程是一票否决机制,只要其中一个预选函数不通过,对应节点则直接被淘汰;剩下通过预选的节点会进入优选阶段,此阶段每个节点会通过对应的优选函数来对各个节点评分,并计算每个节点的总分;最后调度器会根据每个节点的最后总分来挑选一个最高分的节点,作为最终调度结果;如果最高分有多个节点,此时调度器会从对应节点集合中随机挑选一个作为最后调度结果,并把最后调度结果反馈给apiserver;
影响调度的因素
NodeName:nodename是最直接影响pod调度的方式,我们知道调度器评判pod是否被调度,就是根据nodename字段是否为空来进行判断,如果对应pod资源清单中,用户明确定义了nodename字段,则表示不使用调度器调度,此时调度器也不会调度此类pod资源,原因是对应nodename非空,调度器认为该pod是已经调度过了;这种方式是用户手动将pod绑定至某个节点的方式;
NodeSelector:nodeselector相比nodename,这种方式要宽松一些,它也是影响调度器调度的一个重要因素,我们在定义pod资源时,如果指定了nodeselector,就表示只有符合对应node标签选择器定义的标签的node才能运行对应pod;如果没有节点满足节点选择器,对应pod就只能处于pending状态;
Node Affinity:node affinity是用来定义pod对节点的亲和性,所谓pod对节点的亲和性是指,pod更愿意或更不愿意运行在那些节点;这种方式相比前面的nodename和nodeselector在调度逻辑上要精细一些;
Pod Affinity:pod affinity是用来定义pod与pod间的亲和性,所谓pod与pod的亲和性是指,pod更愿意和那个或那些pod在一起;与之相反的也有pod更不愿意和那个或那些pod在一起,这种我们叫做pod anti affinity,即pod与pod间的反亲和性;所谓在一起是指和对应pod在同一个位置,这个位置可以是按主机名划分,也可以按照区域划分,这样一来我们要定义pod和pod在一起或不在一起,定义位置就显得尤为重要,也是评判对应pod能够运行在哪里标准;
taint和tolerations:taint是节点上的污点,tolerations是对应pod对节点上的污点的容忍度,即pod能够容忍节点的污点,那么对应pod就能够运行在对应节点,反之Pod就不能运行在对应节点;这种方式是结合节点的污点,以及pod对节点污点的容忍度来调度的;
示例:使用nodename调度策略
[root@master01 ~]# cat pod-demo.yaml apiVersion: v1 kind: Pod Metadata: name: Nginx-pod spec: nodeName: node01.k8s.org containers: - name: Nginx image: Nginx:1.14-alpine imagePullPolicy: IfNotPresent ports: - name: http containerPort: 80 [root@master01 ~]#
提示:nodename可以直接指定对应pod运行在那个节点上,无需默认调度器调度;以上资源表示把Nginx-pod运行在node01.k8s.org这个节点上;
应用清单
[root@master01 ~]# kubectl apply -f pod-demo.yaml pod/Nginx-pod created [root@master01 ~]# kubectl get pods -o wide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES Nginx-pod 1/1 Running 0 10s 10.244.1.28 node01.k8s.org <none> <none> [root@master01 ~]#
提示:可以看到对应pod一定运行在我们手动指定的节点上;
示例:使用nodeselector调度策略
[root@master01 ~]# cat pod-demo-nodeselector.yaml apiVersion: v1 kind: Pod Metadata: name: Nginx-pod-nodeselector spec: nodeSelector: disktype: ssd containers: - name: Nginx image: Nginx:1.14-alpine imagePullPolicy: IfNotPresent ports: - name: http containerPort: 80 [root@master01 ~]#
提示:nodeselector使用来定义对对应node的标签进行匹配,如果对应节点有此对应标签,则对应pod就能被调度到对应节点运行,反之则不能被调度到对应节点运行;如果所有节点都不满足,此时pod会处于pending状态,直到有对应节点拥有对应标签时,pod才会被调度到对应节点运行;
应用清单
[root@master01 ~]# kubectl apply -f pod-demo-nodeselector.yaml pod/Nginx-pod-nodeselector created [root@master01 ~]# kubectl get pods -o wide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES Nginx-pod 1/1 Running 0 9m38s 10.244.1.28 node01.k8s.org <none> <none> Nginx-pod-nodeselector 0/1 Pending 0 16s <none> <none> <none> <none> [root@master01 ~]#
提示:可以看到对应pod的状态一直处于pending状态,其原因是对应k8s节点没有一个节点满足对应节点选择器标签;
验证:给node02打上对应标签,看看对应pod是否会被调度到node02上呢?
[root@master01 ~]# kubectl get nodes --show-labels NAME STATUS ROLES AGE VERSION LABELS master01.k8s.org Ready control-plane,master 29d v1.20.0 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,kubernetes.io/arch=amd64,kubernetes.io/hostname=master01.k8s.org,kubernetes.io/os=linux,node-role.kubernetes.io/control-plane=,node-role.kubernetes.io/master= node01.k8s.org Ready <none> 29d v1.20.0 app=Nginx-1.14-alpine,beta.kubernetes.io/arch=amd64,kubernetes.io/hostname=node01.k8s.org,kubernetes.io/os=linux node02.k8s.org Ready <none> 29d v1.20.0 beta.kubernetes.io/arch=amd64,kubernetes.io/hostname=node02.k8s.org,kubernetes.io/os=linux node03.k8s.org Ready <none> 29d v1.20.0 beta.kubernetes.io/arch=amd64,kubernetes.io/hostname=node03.k8s.org,kubernetes.io/os=linux node04.k8s.org Ready <none> 19d v1.20.0 beta.kubernetes.io/arch=amd64,kubernetes.io/hostname=node04.k8s.org,kubernetes.io/os=linux [root@master01 ~]# kubectl label node node02.k8s.org disktype=ssd node/node02.k8s.org labeled [root@master01 ~]# kubectl get nodes --show-labels NAME STATUS ROLES AGE VERSION LABELS master01.k8s.org Ready control-plane,disktype=ssd,kubernetes.io/os=linux [root@master01 ~]# kubectl get pods -o wide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES Nginx-pod 1/1 Running 0 12m 10.244.1.28 node01.k8s.org <none> <none> Nginx-pod-nodeselector 1/1 Running 0 3m26s 10.244.2.18 node02.k8s.org <none> <none> [root@master01 ~]#
提示:可以看到给node02节点打上disktype=ssd标签以后,对应pod就被调度在node02上运行;
示例:使用affinity中的nodeaffinity调度策略
[root@master01 ~]# cat pod-demo-affinity-nodeaffinity.yaml apiVersion: v1 kind: Pod Metadata: name: Nginx-pod-nodeaffinity spec: containers: - name: Nginx image: Nginx:1.14-alpine imagePullPolicy: IfNotPresent ports: - name: http containerPort: 80 affinity: nodeAffinity: requiredDuringSchedulingIgnoredDuringExecution: nodeSelectorTerms: - matchExpressions: - key: foo operator: Exists values: [] - matchExpressions: - key: disktype operator: Exists values: [] preferredDuringSchedulingIgnoredDuringExecution: - weight: 10 preference: matchExpressions: - key: foo operator: Exists values: [] - weight: 2 preference: matchExpressions: - key: disktype operator: Exists values: [] [root@master01 ~]#
提示:对于nodeaffinity来说,它有两种限制,一种是硬限制,用requiredDuringSchedulingIgnoredDuringExecution字段来定义,该字段为一个对象,其里面只有nodeSelectorTerms一个字段可以定义,该字段为一个列表对象,可以使用matchExpressions字段来定义匹配对应节点标签的表达式(其中对应表达式中可以使用的操作符有In、NotIn、Exists、DoesNotExists、Lt、Gt;Lt和Gt用于字符串比较,Exists和DoesNotExists用来判断对应标签key是否存在,In和NotIn用来判断对应标签的值是否在某个集合中),也可以使用matchFields字段来定义对应匹配节点字段;所谓硬限制是指必须满足对应定义的节点标签选择表达式或节点字段选择器,对应pod才能够被调度在对应节点上运行,否则对应pod不能被调度到节点上运行,如果没有满足对应的节点标签表达式或节点字段选择器,则对应pod会一直被挂起;第二种是软限制,用preferredDuringSchedulingIgnoredDuringExecution字段定义,该字段为一个列表对象,里面可以用weight来定义对应软限制的权重,该权重会被调度器在最后计算node得分时加入到对应节点总分中;preference字段是用来定义对应软限制匹配条件;即满足对应软限制的节点在调度时会被调度器把对应权重加入对应节点总分;对于软限制来说,只有当硬限制匹配有多个node时,对应软限制才会生效;即软限制是在硬限制的基础上做的第二次限制,它表示在硬限制匹配多个node,优先使用软限制中匹配的node,如果软限制中给定的权重和匹配条件不能让多个node决胜出最高分,即使用默认调度调度机制,从多个最高分node中随机挑选一个node作为最后调度结果;如果在软限制中给定权重和对应匹配条件能够决胜出对应node最高分,则对应node就为最后调度结果;简单讲软限制和硬限制一起使用,软限制是辅助硬限制对node进行挑选;如果只是单纯的使用软限制,则优先把pod调度到权重较高对应条件匹配的节点上;如果权重一样,则调度器会根据默认规则从最后得分中挑选一个最高分,作为最后调度结果;以上示例表示运行pod的硬限制必须是对应节点上满足有key为foo的节点标签或者key为disktype的节点标签;如果对应硬限制没有匹配到任何节点,则对应pod不做任何调度,即处于pending状态,如果对应硬限制都匹配,则在软限制中匹配key为foo的节点将在总分中加上10,对key为disktype的节点总分加2分;即软限制中,pod更倾向key为foo的节点标签的node上;这里需要注意的是nodeAffinity没有node anti Affinity,要想实现反亲和性可以使用NotIn或者DoesNotExists操作符来匹配对应条件;
应用资源清单
[root@master01 ~]# kubectl get nodes -L foo,disktype NAME STATUS ROLES AGE VERSION FOO DISKTYPE master01.k8s.org Ready control-plane,master 29d v1.20.0 node01.k8s.org Ready <none> 29d v1.20.0 node02.k8s.org Ready <none> 29d v1.20.0 ssd node03.k8s.org Ready <none> 29d v1.20.0 node04.k8s.org Ready <none> 19d v1.20.0 [root@master01 ~]# kubectl apply -f pod-demo-affinity-nodeaffinity.yaml pod/Nginx-pod-nodeaffinity created [root@master01 ~]# kubectl get pods -o wide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES Nginx-pod 1/1 Running 0 122m 10.244.1.28 node01.k8s.org <none> <none> Nginx-pod-nodeaffinity 1/1 Running 0 7s 10.244.2.22 node02.k8s.org <none> <none> Nginx-pod-nodeselector 1/1 Running 0 113m 10.244.2.18 node02.k8s.org <none> <none> [root@master01 ~]#
提示:可以看到应用清单以后对应pod被调度到node02上运行了,之所以调度到node02是因为对应节点上有key为disktype的节点标签,该条件满足对应运行pod的硬限制;
验证:删除pod和对应node02上的key为disktype的节点标签,再次应用资源清单,看看对应pod怎么调度?
[root@master01 ~]# kubectl delete -f pod-demo-affinity-nodeaffinity.yaml pod "Nginx-pod-nodeaffinity" deleted [root@master01 ~]# kubectl label node node02.k8s.org disktype- node/node02.k8s.org labeled [root@master01 ~]# kubectl get pods NAME READY STATUS RESTARTS AGE Nginx-pod 1/1 Running 0 127m Nginx-pod-nodeselector 1/1 Running 0 118m [root@master01 ~]# kubectl get node -L foo,disktype NAME STATUS ROLES AGE VERSION FOO DISKTYPE master01.k8s.org Ready control-plane,master 29d v1.20.0 node01.k8s.org Ready <none> 29d v1.20.0 node02.k8s.org Ready <none> 29d v1.20.0 node03.k8s.org Ready <none> 29d v1.20.0 node04.k8s.org Ready <none> 19d v1.20.0 [root@master01 ~]# kubectl apply -f pod-demo-affinity-nodeaffinity.yaml pod/Nginx-pod-nodeaffinity created [root@master01 ~]# kubectl get pods -o wide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES Nginx-pod 1/1 Running 0 128m 10.244.1.28 node01.k8s.org <none> <none> Nginx-pod-nodeaffinity 0/1 Pending 0 9s <none> <none> <none> <none> Nginx-pod-nodeselector 1/1 Running 0 118m 10.244.2.18 node02.k8s.org <none> <none> [root@master01 ~]#
提示:可以看到删除原有pod和node2上面的标签后,再次应用资源清单,pod就一直处于pending状态;其原因是对应k8s节点没有满足对应pod运行时的硬限制;所以对应pod无法进行调度;
验证:删除pod,分别给node01和node03打上key为foo和key为disktype的节点标签,看看然后再次应用清单,看看对应pod会这么调度?
[root@master01 ~]# kubectl delete -f pod-demo-affinity-nodeaffinity.yaml pod "Nginx-pod-nodeaffinity" deleted [root@master01 ~]# kubectl label node node01.k8s.org foo=bar node/node01.k8s.org labeled [root@master01 ~]# kubectl label node node03.k8s.org disktype=ssd node/node03.k8s.org labeled [root@master01 ~]# kubectl get nodes -L foo,master 29d v1.20.0 node01.k8s.org Ready <none> 29d v1.20.0 bar node02.k8s.org Ready <none> 29d v1.20.0 node03.k8s.org Ready <none> 29d v1.20.0 ssd node04.k8s.org Ready <none> 19d v1.20.0 [root@master01 ~]# kubectl apply -f pod-demo-affinity-nodeaffinity.yaml pod/Nginx-pod-nodeaffinity created [root@master01 ~]# kubectl get pods -o wide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES Nginx-pod 1/1 Running 0 132m 10.244.1.28 node01.k8s.org <none> <none> Nginx-pod-nodeaffinity 1/1 Running 0 5s 10.244.1.29 node01.k8s.org <none> <none> Nginx-pod-nodeselector 1/1 Running 0 123m 10.244.2.18 node02.k8s.org <none> <none> [root@master01 ~]#
提示:可以看到当硬限制中的条件被多个node匹配时,优先调度对应软限制条件匹配权重较大的节点上,即硬限制不能正常抉择出调度节点,则软限制中对应权重大的匹配条件有限被调度;
验证:删除node01上的节点标签,看看对应pod是否会被移除,或被调度其他节点?
[root@master01 ~]# kubectl get nodes -L foo,master 29d v1.20.0 node01.k8s.org Ready <none> 29d v1.20.0 bar node02.k8s.org Ready <none> 29d v1.20.0 node03.k8s.org Ready <none> 29d v1.20.0 ssd node04.k8s.org Ready <none> 19d v1.20.0 [root@master01 ~]# kubectl label node node01.k8s.org foo- node/node01.k8s.org labeled [root@master01 ~]# kubectl get nodes -L foo,master 29d v1.20.0 node01.k8s.org Ready <none> 29d v1.20.0 node02.k8s.org Ready <none> 29d v1.20.0 node03.k8s.org Ready <none> 29d v1.20.0 ssd node04.k8s.org Ready <none> 19d v1.20.0 [root@master01 ~]# kubectl get pods -o wide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES Nginx-pod 1/1 Running 0 145m 10.244.1.28 node01.k8s.org <none> <none> Nginx-pod-nodeaffinity 1/1 Running 0 12m 10.244.1.29 node01.k8s.org <none> <none> Nginx-pod-nodeselector 1/1 Running 0 135m 10.244.2.18 node02.k8s.org <none> <none> [root@master01 ~]#
提示:可以看到当pod正常运行以后,即便后来对应节点不满足对应pod运行的硬限制,对应pod也不会被移除或调度到其他节点,说明节点亲和性是在调度时发生作用,一旦调度完成,即便后来节点不满足pod运行节点亲和性,对应pod也不会被移除或再次调度;简单讲nodeaffinity对pod调度既成事实无法做二次调度;
node Affinity规则生效方式
1、nodeAffinity和nodeSelector一起使用时,两者间关系取“与”关系,即两者条件必须同时满足,对应节点才满足调度运行或不运行对应pod;
示例:使用nodeaffinity和nodeselector定义pod调度策略
[root@master01 ~]# cat pod-demo-affinity-nodesector.yaml apiVersion: v1 kind: Pod Metadata: name: Nginx-pod-nodeaffinity-nodeselector spec: containers: - name: Nginx image: Nginx:1.14-alpine imagePullPolicy: IfNotPresent ports: - name: http containerPort: 80 affinity: nodeAffinity: requiredDuringSchedulingIgnoredDuringExecution: nodeSelectorTerms: - matchExpressions: - key: foo operator: Exists values: [] nodeSelector: disktype: ssd [root@master01 ~]#
提示:以上清单表示对应pod倾向运行在节点上有节点标签key为foo的节点并且对应节点上还有disktype=ssd节点标签
应用清单
[root@master01 ~]# kubectl get nodes -L foo,disktype NAME STATUS ROLES AGE VERSION FOO DISKTYPE master01.k8s.org Ready control-plane,master 29d v1.20.0 node01.k8s.org Ready <none> 29d v1.20.0 node02.k8s.org Ready <none> 29d v1.20.0 node03.k8s.org Ready <none> 29d v1.20.0 ssd node04.k8s.org Ready <none> 19d v1.20.0 [root@master01 ~]# kubectl apply -f pod-demo-affinity-nodesector.yaml pod/Nginx-pod-nodeaffinity-nodeselector created [root@master01 ~]# kubectl get pods -o wide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES Nginx-pod 1/1 Running 0 168m 10.244.1.28 node01.k8s.org <none> <none> Nginx-pod-nodeaffinity 1/1 Running 0 35m 10.244.1.29 node01.k8s.org <none> <none> Nginx-pod-nodeaffinity-nodeselector 0/1 Pending 0 7s <none> <none> <none> <none> Nginx-pod-nodeselector 1/1 Running 0 159m 10.244.2.18 node02.k8s.org <none> <none> [root@master01 ~]#
提示:可以看到对应pod被创建以后,一直处于pengding状态,原因是没有节点满足同时有节点标签key为foo并且disktype=ssd的节点,所以对应pod就无法正常被调度,只好挂起;
2、多个nodeaffinity同时指定多个nodeSelectorTerms时,相互之间取“或”关系;即使用多个matchExpressions列表分别指定对应的匹配条件;
[root@master01 ~]# cat pod-demo-affinity2.yaml apiVersion: v1 kind: Pod Metadata: name: Nginx-pod-nodeaffinity2 spec: containers: - name: Nginx image: Nginx:1.14-alpine imagePullPolicy: IfNotPresent ports: - name: http containerPort: 80 affinity: nodeAffinity: requiredDuringSchedulingIgnoredDuringExecution: nodeSelectorTerms: - matchExpressions: - key: foo operator: Exists values: [] - matchExpressions: - key: disktype operator: Exists values: [] [root@master01 ~]#
提示:以上示例表示运行pod节点倾向对应节点上有节点标签key为foo或key为disktype的节点;
应用清单
[root@master01 ~]# kubectl get nodes -L foo,master 29d v1.20.0 node01.k8s.org Ready <none> 29d v1.20.0 node02.k8s.org Ready <none> 29d v1.20.0 node03.k8s.org Ready <none> 29d v1.20.0 ssd node04.k8s.org Ready <none> 19d v1.20.0 [root@master01 ~]# kubectl apply -f pod-demo-affinity2.yaml pod/Nginx-pod-nodeaffinity2 created [root@master01 ~]# kubectl get pods -o wide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES Nginx-pod 1/1 Running 0 179m 10.244.1.28 node01.k8s.org <none> <none> Nginx-pod-nodeaffinity 1/1 Running 0 46m 10.244.1.29 node01.k8s.org <none> <none> Nginx-pod-nodeaffinity-nodeselector 0/1 Pending 0 10m <none> <none> <none> <none> Nginx-pod-nodeaffinity2 1/1 Running 0 6s 10.244.3.21 node03.k8s.org <none> <none> Nginx-pod-nodeselector 1/1 Running 0 169m 10.244.2.18 node02.k8s.org <none> <none> [root@master01 ~]#
提示:可以看到对应pod被调度node03上运行了,之所以能在node03运行是因为对应node03满足节点标签key为foo或key为disktype条件;
3、同一个matchExpressions,多个条件取“与”关系;即使用多个key列表分别指定对应的匹配条件;
示例:在一个matchExpressions下指定多个条件
[root@master01 ~]# cat pod-demo-affinity3.yaml apiVersion: v1 kind: Pod Metadata: name: Nginx-pod-nodeaffinity3 spec: containers: - name: Nginx image: Nginx:1.14-alpine imagePullPolicy: IfNotPresent ports: - name: http containerPort: 80 affinity: nodeAffinity: requiredDuringSchedulingIgnoredDuringExecution: nodeSelectorTerms: - matchExpressions: - key: foo operator: Exists values: [] - key: disktype operator: Exists values: [] [root@master01 ~]#
提示:上述清单表示pod倾向运行在节点标签key为foo和节点标签key为disktype的节点上;
应用清单
[root@master01 ~]# kubectl get nodes -L foo,disktype NAME STATUS ROLES AGE VERSION FOO DISKTYPE master01.k8s.org Ready control-plane,master 29d v1.20.0 node01.k8s.org Ready <none> 29d v1.20.0 node02.k8s.org Ready <none> 29d v1.20.0 node03.k8s.org Ready <none> 29d v1.20.0 ssd node04.k8s.org Ready <none> 19d v1.20.0 [root@master01 ~]# kubectl apply -f pod-demo-affinity3.yaml pod/Nginx-pod-nodeaffinity3 created [root@master01 ~]# kubectl get pods -o wide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES Nginx-pod 1/1 Running 0 3h8m 10.244.1.28 node01.k8s.org <none> <none> Nginx-pod-nodeaffinity 1/1 Running 0 56m 10.244.1.29 node01.k8s.org <none> <none> Nginx-pod-nodeaffinity-nodeselector 0/1 Pending 0 20m <none> <none> <none> <none> Nginx-pod-nodeaffinity2 1/1 Running 0 9m38s 10.244.3.21 node03.k8s.org <none> <none> Nginx-pod-nodeaffinity3 0/1 Pending 0 7s <none> <none> <none> <none> Nginx-pod-nodeselector 1/1 Running 0 179m 10.244.2.18 node02.k8s.org <none> <none> [root@master01 ~]#
提示:可以看到对应pod创建以后,一直处于pengding状态;原因是没有符合节点标签同时满足key为foo和key为disktyp的节点;
pod affinity 的工作逻辑和使用方式同node affinity类似,pod affinity也有硬限制和软限制,其逻辑和nodeaffinity一样,即定义了硬亲和,软亲和规则就是辅助硬亲和规则挑选对应pod运行节点;如果硬亲和不满足条件,对应pod只能挂起;如果只是使用软亲和规则,则对应pod会优先运行在匹配软亲和规则中权重较大的节点上,如果软亲和规则也没有节点满足,则使用默认调度规则从中挑选一个得分最高的节点运行pod;
示例:使用Affinity中的PodAffinity中的硬限制调度策略
[root@master01 ~]# cat require-podaffinity.yaml apiVersion: v1 kind: Pod Metadata: name: with-pod-affinity-1 spec: affinity: podAffinity: requiredDuringSchedulingIgnoredDuringExecution: - labelSelector: matchExpressions: - {key: app,operator: In,values: ["Nginx"]} topologyKey: kubernetes.io/hostname containers: - name: myapp image: ikubernetes/myapp:v1 [root@master01 ~]#
提示:上述清单是podaffinity中的硬限制使用方式,其中定义podaffinity需要在spec.affinity字段中使用podAffinity字段来定义;requiredDuringSchedulingIgnoredDuringExecution字段是定义对应podAffinity的硬限制所使用的字段,该字段为一个列表对象,其中labelSelector用来定义和对应pod在一起pod的标签选择器;topologyKey字段是用来定义对应在一起的位置以那个什么来划分,该位置可以是对应节点上的一个节点标签key;上述清单表示运行myapp这个pod的硬限制条件是必须满足对应对应节点上必须运行的有一个pod,这个pod上有一个app=Nginx的标签;即标签为app=Nginx的pod运行在那个节点,对应myapp就运行在那个节点;如果没有对应pod存在,则该pod也会处于pending状态;
应用清单
[root@master01 ~]# kubectl get pods -L app -o wide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES APP Nginx-pod 1/1 Running 0 8m25s 10.244.4.25 node04.k8s.org <none> <none> Nginx [root@master01 ~]# kubectl apply -f require-podaffinity.yaml pod/with-pod-affinity-1 created [root@master01 ~]# kubectl get pods -L app -o wide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES APP Nginx-pod 1/1 Running 0 8m43s 10.244.4.25 node04.k8s.org <none> <none> Nginx with-pod-affinity-1 1/1 Running 0 6s 10.244.4.26 node04.k8s.org <none> <none> [root@master01 ~]#
提示:可以看到对应pod运行在node04上了,其原因对应节点上有一个app=Nginx标签的pod存在,满足对应podAffinity中的硬限制;
验证:删除上述两个pod,然后再次应用清单,看看对应pod是否能够正常运行?
[root@master01 ~]# kubectl delete all --all pod "Nginx-pod" deleted pod "with-pod-affinity-1" deleted service "kubernetes" deleted [root@master01 ~]# kubectl apply -f require-podaffinity.yaml pod/with-pod-affinity-1 created [root@master01 ~]# kubectl get pods -o wide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES with-pod-affinity-1 0/1 Pending 0 8s <none> <none> <none> <none> [root@master01 ~]#
提示:可以看到对应pod处于pending状态,其原因是没有一个节点上运行的有app=Nginx pod标签,不满足podAffinity中的硬限制;
示例:使用Affinity中的PodAffinity中的软限制调度策略
[root@master01 ~]# cat prefernece-podaffinity.yaml apiVersion: v1 kind: Pod Metadata: name: with-pod-affinity-2 spec: affinity: podAffinity: preferredDuringSchedulingIgnoredDuringExecution: - weight: 80 podAffinityTerm: labelSelector: matchExpressions: - {key: app,values: ["db"]} topologyKey: rack - weight: 20 podAffinityTerm: labelSelector: matchExpressions: - {key: app,values: ["db"]} topologyKey: zone containers: - name: myapp image: ikubernetes/myapp:v1 [root@master01 ~]#
提示:podAffinity中的软限制需要用preferredDuringSchedulingIgnoredDuringExecution字段定义;其中weight用来定义对应软限制条件的权重,即满足对应软限制的node,最后得分会加上这个权重;上述清单表示以节点标签key=rack来划分位置,如果对应节点上运行的有对应pod标签为app=db的pod,则对应节点总分加80;如果以节点标签key=zone来划分位置,如果对应节点上运行的有pod标签为app=db的pod,对应节点总分加20;如果没有满足的节点,则使用默认调度规则进行调度;
应用清单
[root@master01 ~]# kubectl get node -L rack,zone NAME STATUS ROLES AGE VERSION RACK ZONE master01.k8s.org Ready control-plane,master 30d v1.20.0 node01.k8s.org Ready <none> 30d v1.20.0 node02.k8s.org Ready <none> 30d v1.20.0 node03.k8s.org Ready <none> 30d v1.20.0 node04.k8s.org Ready <none> 20d v1.20.0 [root@master01 ~]# kubectl get pods -o wide -L app NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES APP with-pod-affinity-1 0/1 Pending 0 22m <none> <none> <none> <none> [root@master01 ~]# kubectl apply -f prefernece-podaffinity.yaml pod/with-pod-affinity-2 created [root@master01 ~]# kubectl get pods -o wide -L app NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES APP with-pod-affinity-1 0/1 Pending 0 22m <none> <none> <none> <none> with-pod-affinity-2 1/1 Running 0 6s 10.244.4.28 node04.k8s.org <none> <none> [root@master01 ~]#
提示:可以看到对应pod正常运行起来,并调度到node04上;从上面的示例来看,对应pod的运行并没有走软限制条件进行调度,而是走默认调度法则;其原因是对应节点没有满足对应软限制中的条件;
验证:删除pod,在node01上打上rack节点标签,在node03上打上zone节点标签,再次运行pod,看看对应pod会怎么调度?
[root@master01 ~]# kubectl delete -f prefernece-podaffinity.yaml pod "with-pod-affinity-2" deleted [root@master01 ~]# kubectl label node node01.k8s.org rack=group1 node/node01.k8s.org labeled [root@master01 ~]# kubectl label node node03.k8s.org zone=group2 node/node03.k8s.org labeled [root@master01 ~]# kubectl get node -L rack,zone NAME STATUS ROLES AGE VERSION RACK ZONE master01.k8s.org Ready control-plane,master 30d v1.20.0 node01.k8s.org Ready <none> 30d v1.20.0 group1 node02.k8s.org Ready <none> 30d v1.20.0 node03.k8s.org Ready <none> 30d v1.20.0 group2 node04.k8s.org Ready <none> 20d v1.20.0 [root@master01 ~]# kubectl apply -f prefernece-podaffinity.yaml pod/with-pod-affinity-2 created [root@master01 ~]# kubectl get pods -o wide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES with-pod-affinity-1 0/1 Pending 0 27m <none> <none> <none> <none> with-pod-affinity-2 1/1 Running 0 9s 10.244.4.29 node04.k8s.org <none> <none> [root@master01 ~]#
提示:可以看到对应pod还是被调度到node04上运行,说明节点上的位置标签不影响其调度结果;
验证:删除pod,在node01和node03上分别创建一个标签为app=db的pod,然后再次应用清单,看看对应pod会这么调度?
[root@master01 ~]# kubectl apply -f prefernece-podaffinity.yaml pod/with-pod-affinity-2 created [root@master01 ~]# kubectl get pods -o wide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES with-pod-affinity-1 0/1 Pending 0 27m <none> <none> <none> <none> with-pod-affinity-2 1/1 Running 0 9s 10.244.4.29 node04.k8s.org <none> <none> [root@master01 ~]# [root@master01 ~]# kubectl delete -f prefernece-podaffinity.yaml pod "with-pod-affinity-2" deleted [root@master01 ~]# cat pod-demo.yaml apiVersion: v1 kind: Pod Metadata: name: redis-pod1 labels: app: db spec: nodeSelector: rack: group1 containers: - name: redis image: redis:4-alpine imagePullPolicy: IfNotPresent ports: - name: redis containerPort: 6379 --- apiVersion: v1 kind: Pod Metadata: name: redis-pod2 labels: app: db spec: nodeSelector: zone: group2 containers: - name: redis image: redis:4-alpine imagePullPolicy: IfNotPresent ports: - name: redis containerPort: 6379 [root@master01 ~]# kubectl apply -f pod-demo.yaml pod/redis-pod1 created pod/redis-pod2 created [root@master01 ~]# kubectl get pods -L app -o wide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES APP redis-pod1 1/1 Running 0 34s 10.244.1.35 node01.k8s.org <none> <none> db redis-pod2 1/1 Running 0 34s 10.244.3.24 node03.k8s.org <none> <none> db with-pod-affinity-1 0/1 Pending 0 34m <none> <none> <none> <none> [root@master01 ~]# kubectl apply -f prefernece-podaffinity.yaml pod/with-pod-affinity-2 created [root@master01 ~]# kubectl get pods -L app -o wide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES APP redis-pod1 1/1 Running 0 52s 10.244.1.35 node01.k8s.org <none> <none> db redis-pod2 1/1 Running 0 52s 10.244.3.24 node03.k8s.org <none> <none> db with-pod-affinity-1 0/1 Pending 0 35m <none> <none> <none> <none> with-pod-affinity-2 1/1 Running 0 9s 10.244.1.36 node01.k8s.org <none> <none> [root@master01 ~]#
提示:可以看到对应pod运行在node01上,其原因是对应node01上有一个pod标签为app=db的pod运行,满足对应软限制条件,并且对应节点上有key为rack的节点标签;即满足对应权重为80的条件,所以对应pod更倾向运行在node01上;
示例:使用Affinity中的PodAffinity中的硬限制和软限制调度策略
[root@master01 ~]# cat require-preference-podaffinity.yaml apiVersion: v1 kind: Pod Metadata: name: with-pod-affinity-3 spec: affinity: podAffinity: requiredDuringSchedulingIgnoredDuringExecution: - labelSelector: matchExpressions: - {key: app,values: ["db"]} topologyKey: kubernetes.io/hostname preferredDuringSchedulingIgnoredDuringExecution: - weight: 80 podAffinityTerm: labelSelector: matchExpressions: - {key: app,values: ["db"]} topologyKey: zone containers: - name: myapp image: ikubernetes/myapp:v1 [root@master01 ~]#
提示:上述清单表示对应pod必须运行在对应节点上运行的有标签为app=db的pod,如果没有节点满足,则对应pod只能挂起;如果满足的节点有多个,则对应满足软限制中的要求;如果满足硬限制的同时也满足对应节点上有key为rack的节点标签,则对应节点总分加80,如果对应节点有key为zone的节点标签,则对应节点总分加20;
应用清单
[root@master01 ~]# kubectl get pods -o wide -L app NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES APP redis-pod1 1/1 Running 0 13m 10.244.1.35 node01.k8s.org <none> <none> db redis-pod2 1/1 Running 0 13m 10.244.3.24 node03.k8s.org <none> <none> db with-pod-affinity-1 0/1 Pending 0 48m <none> <none> <none> <none> with-pod-affinity-2 1/1 Running 0 13m 10.244.1.36 node01.k8s.org <none> <none> [root@master01 ~]# kubectl apply -f require-preference-podaffinity.yaml pod/with-pod-affinity-3 created [root@master01 ~]# kubectl get pods -o wide -L app NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES APP redis-pod1 1/1 Running 0 14m 10.244.1.35 node01.k8s.org <none> <none> db redis-pod2 1/1 Running 0 14m 10.244.3.24 node03.k8s.org <none> <none> db with-pod-affinity-1 0/1 Pending 0 48m <none> <none> <none> <none> with-pod-affinity-2 1/1 Running 0 13m 10.244.1.36 node01.k8s.org <none> <none> with-pod-affinity-3 1/1 Running 0 6s 10.244.1.37 node01.k8s.org <none> <none> [root@master01 ~]#
提示:可以看到对应pod被调度到node01上运行,其原因是对应节点满足硬限制条件的同时也满足对应权重最大的软限制条件;
验证:删除上述pod,重新应用清单看看对应pod是否还会正常运行?
[root@master01 ~]# kubectl delete all --all pod "redis-pod1" deleted pod "redis-pod2" deleted pod "with-pod-affinity-1" deleted pod "with-pod-affinity-2" deleted pod "with-pod-affinity-3" deleted service "kubernetes" deleted [root@master01 ~]# kubectl apply -f require-preference-podaffinity.yaml pod/with-pod-affinity-3 created [root@master01 ~]# kubectl get pods -o wide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES with-pod-affinity-3 0/1 Pending 0 5s <none> <none> <none> <none> [root@master01 ~]#
提示:可以看到对应pod创建出来处于pending状态,其原因是没有任何节点满足对应pod调度的硬限制;所以对应pod没法调度,只能被挂起;
示例:使用Affinity中的podAntiAffinity调度策略
[root@master01 ~]# cat require-preference-podantiaffinity.yaml apiVersion: v1 kind: Pod Metadata: name: with-pod-affinity-4 spec: affinity: podAntiAffinity: requiredDuringSchedulingIgnoredDuringExecution: - labelSelector: matchExpressions: - {key: app,values: ["db"]} topologyKey: zone containers: - name: myapp image: ikubernetes/myapp:v1 [root@master01 ~]#
提示:podantiaffinity的使用和podaffinity的使用方式一样,只是其对应的逻辑相反,podantiaffinity是定义满足条件的节点不运行对应pod,podaffinity是满足条件运行pod;上述清单表示对应pod一定不能运行在有标签为app=db的pod运行的节点,并且对应节点上如果有key为rack和key为zone的节点标签,这类节点也不运行;即只能运行在上述三个条件都满足的节点上;如果所有节点都满足上述三个条件,则对应pod只能挂;如果单单使用软限制,则pod会勉强运行在对应节点得分较低的节点上运行;
应用清单
[root@master01 ~]# kubectl get pods -o wide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES with-pod-affinity-3 0/1 Pending 0 22m <none> <none> <none> <none> [root@master01 ~]# kubectl apply -f require-preference-podantiaffinity.yaml pod/with-pod-affinity-4 created [root@master01 ~]# kubectl get pods -o wide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES with-pod-affinity-3 0/1 Pending 0 22m <none> <none> <none> <none> with-pod-affinity-4 1/1 Running 0 6s 10.244.4.30 node04.k8s.org <none> <none> [root@master01 ~]# kubectl get node -L rack,master 30d v1.20.0 node01.k8s.org Ready <none> 30d v1.20.0 group1 node02.k8s.org Ready <none> 30d v1.20.0 node03.k8s.org Ready <none> 30d v1.20.0 group2 node04.k8s.org Ready <none> 20d v1.20.0 [root@master01 ~]#
提示:可以看到对应pod被调度到node04上运行;其原因是node04上没有上述三个条件;当然node02也是符合运行对应pod的节点;
验证:删除上述pod,在四个节点上各自运行一个app=db标签的pod,再次应用清单,看看对用pod怎么调度?
[root@master01 ~]# kubectl delete all --all pod "with-pod-affinity-3" deleted pod "with-pod-affinity-4" deleted service "kubernetes" deleted [root@master01 ~]# cat pod-demo.yaml apiVersion: apps/v1 kind: DaemonSet Metadata: name: redis-ds labels: app: db spec: selector: matchLabels: app: db template: Metadata: labels: app: db spec: containers: - name: redis image: redis:4-alpine ports: - name: redis containerPort: 6379 [root@master01 ~]# kubectl apply -f pod-demo.yaml daemonset.apps/redis-ds created [root@master01 ~]# kubectl get pods -L app -o wide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES APP redis-ds-4bnmv 1/1 Running 0 44s 10.244.2.26 node02.k8s.org <none> <none> db redis-ds-c2h77 1/1 Running 0 44s 10.244.1.38 node01.k8s.org <none> <none> db redis-ds-mbxcd 1/1 Running 0 44s 10.244.4.32 node04.k8s.org <none> <none> db redis-ds-r2kxv 1/1 Running 0 44s 10.244.3.25 node03.k8s.org <none> <none> db [root@master01 ~]# kubectl apply -f require-preference-podantiaffinity.yaml pod/with-pod-affinity-5 created [root@master01 ~]# kubectl get pods -o wide -L app NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES APP redis-ds-4bnmv 1/1 Running 0 2m29s 10.244.2.26 node02.k8s.org <none> <none> db redis-ds-c2h77 1/1 Running 0 2m29s 10.244.1.38 node01.k8s.org <none> <none> db redis-ds-mbxcd 1/1 Running 0 2m29s 10.244.4.32 node04.k8s.org <none> <none> db redis-ds-r2kxv 1/1 Running 0 2m29s 10.244.3.25 node03.k8s.org <none> <none> db with-pod-affinity-5 0/1 Pending 0 9s <none> <none> <none> <none> [root@master01 ~]#
提示:可以看到对应pod没有节点可以运行,处于pending状态,其原因对应节点都满足排斥运行对应pod的硬限制;
通过上述验证过程可以总结,不管是pod与节点的亲和性还是pod与pod的亲和性,只要在调度策略中定义了硬亲和,对应pod一定会运行在满足硬亲和条件的节点上,如果没有节点满足硬亲和条件,则对应pod挂起;如果只是定义了软亲和,则对应pod会优先运行在匹配权重较大软限制条件的节点上,如果没有节点满足软限制,对应调度就走默认调度策略,找得分最高的节点运行;对于反亲和性也是同样的逻辑;不同的是反亲和满足对应硬限制或软限制,对应pod不会运行在对应节点上;这里还需要注意一点,使用pod与pod的亲和调度策略,如果节点较多,其规则不应该设置的过于精细,颗粒度应该适当即可,过度精细会导致pod在调度时,筛选节点消耗更多的资源,导致整个集群性能下降;建议在大规模集群中使用node affinity;
原文链接:/kubernetes/995361.html