Producers发布记录到集群,集群维护这些记录并且将记录分发给Consumers。
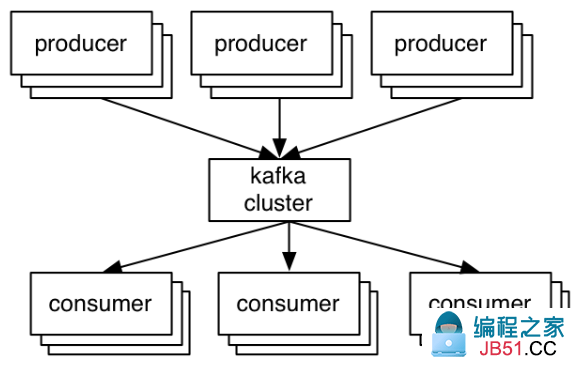
在Kafka中,最关键的抽象是topic。Producers发布记录到一个topic,Consumers订阅一个或多个topic。Topic是一个分片的写优先的log。Producers追加记录到这些logs,Consumers订阅logs的改变。每条记录都是一个key/value对。根据key来指定记录到哪个日志分区(除非发布者直接指定分区)。
下面是一个简单的例子,在这个例子中,有一个生产者和一个消费者,它们读写一个有两个分区的topic:
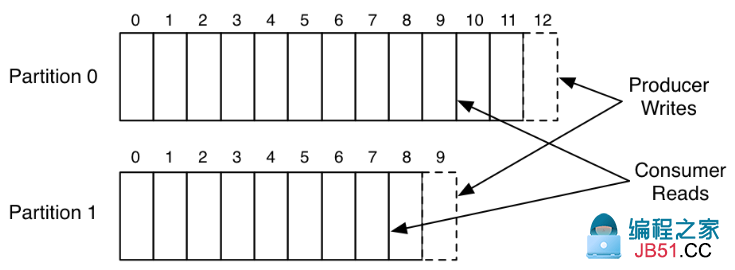
这张图显示了一个生产者进程追加记录到两个分区日志。日志中的每条记录有有一个offset。Consumer用这个offset来描述它在每个日志中的位置。
Partitions是分布在集群的机器之上的。(PS:一堆机器组成一个集群,集群之上是topic,而topic是由多个partitions组成)
不想其它的消息系统那样,Kafka的log总是持久化的。消息在到达kafka的时候立刻被写到文件系统。消息被消费以后不会被删除,至于保留多长时间取决于配置。这使得kafka能够支持高效的发布订阅,因为不管有多少消费者它们都共享一个log。
为了容错,kafka也复制logs到多个服务器。
当Producers发布一个消息的时候,它会得到一个确认,这个确认中包含了这条记录的offset。第一个被发布到分区的记录的offset是0,第二条记录是1,以此递增。Consumers从指定offset处开始消费,并且定期保存它们的位置在log中:保存这个offset是为了以防万一消费者实例崩溃了,另一个实例可以继续从这个位置开始消费。
Replication
Kafka根据配置的服务器数量来复制每个分区的日志。默认情况下,kafka是开启复制的,事实上,未复制的主题和复制的主题是一样的,只不过它们的复制因子是1。
复制是以分区为单位的(The unit of replication is the topic partition)。Kafka中,每个分区都有一个leader和0个或多个followers。副本的总数量包括leader。所有的读和写都指向分区的leader。通常,分区的数量比broker要多,而且分区分布在broker中。
Followers就像正常的kafka消费者那样从leader那里消费消息,并且把它们应用到自己的log中。
想大多数分布式系统自动处理失败那样,关于一个节点"alive"需要有一个明确的定义,kafka中结点存活有两个条件:
1、一个节点必须能够在Zookeeper上维护它自己的会话(通过Zookeeper的心跳机制)
2、如果这个节点是一个slave,那么它必须复制leader上发送的写操作,而且不能落后太多
为了避免同"alive"和"fail"混淆,我们把满足这两个条件的结点状态称之为"in sync"。leader维持对"in sync"结点的跟踪。如果一个follower死了,或者卡了,或者失败了,leader会将其从同步副本列表中删除。
我们现在可以更明确的定义,当这个分区的所有in sync副本都应用了这个log时一个消息才能算是提交完成。只有提交完成的消息才能分发给消费者。这就意味着消费者不需要担心会看到一个可能丢失的消息。另一方面,生产者有一些选项可以控制到底是等待这个消息提交完成还是不等待,当然这取决于它们在持久化和延迟之间的这种的性能。这个性能有生产者的acks设置来控制。注意,topic关于in-sync副本有一个设置叫"minimum number",当生产者请求一个已经被写到所有in-sync副本上的消息的确认的时候会检查这个设置。如果生产者确认请求不那么严格,那么这个消息仍然可以被提交,被消费,即使in-sync副本的数量比minimum小。
Kafka保证在任何时候,只有有一个in sync副本还活着,已经提交的消息就不会丢失。
We can now more precisely define that a message is considered committed when all in sync replicas for that partition have applied it to their log. Only committed messages are ever given out to the consumer. This means that the consumer need not worry about potentially seeing a message that could be lost if the leader fails. Producers,on the other hand,have the option of either waiting for the message to be committed or not,depending on their preference for tradeoff between latency and durability. This preference is controlled by the acks setting that the producer uses. Note that topics have a setting for the "minimum number" of in-sync replicas that is checked when the producer requests acknowledgment that a message has been written to the full set of in-sync replicas. If a less stringent acknowledgement is requested by the producer,then the message can be committed,and consumed,even if the number of in-sync replicas is lower than the minimum (e.g. it can be as low as just the leader).
The guarantee that Kafka offers is that a committed message will not be lost,as long as there is at least one in sync replica alive,at all times.
参考
http://kafka.apache.org/documentation/#design
https://engineering.linkedin.com/kafka/benchmarking-apache-kafka-2-million-writes-second-three-cheap-machines
原文链接:/kafka/882812.html
