1、配置集群
(1)在yarn-env.sh中配置JAVA_HOME
export JAVA_HOME=/opt/module/jdk1.8.0_11
(2)在yarn-site.xml中配置
<!--Reducer获取数据的方式--> <property> name>yarn.nodemanager.aux-services</value>mapreduce_shuffle> 指定yarn的ResourceManager的地址>yarn.resourcemanager.hostname>hadoop01>
(3)配置mapred-env.sh
export JAVA_HOME=/opt/module/jdk1.8.0_11
(4)将mapred-site.xml.template重命名为mapred-site.xml
mv mapred-site.xml.template mapred-site.xml
并配置:
指定MR运行在yarn上>mapreduce.framework.name>yarn>
二、启动集群
确保NameNode和Datanode已经启动,用jps查看,若没启动,则进行启动(在hadoop-2.9.2目录下)
sbin/hadoop-daemon.sh start namenode
sbin/hadoop-daemon.sh start datanode

(1) 启动ResourceManager
sbin/yarn-daemon.sh start resourcemanager
(2)启动NodeManager
sbin/yarn-daemon.sh start nodemanager

systemctl status firewalld.service查看防火墙状态
systemctl stop firewalld.service 关闭运行的防火墙
(3) 查看集群
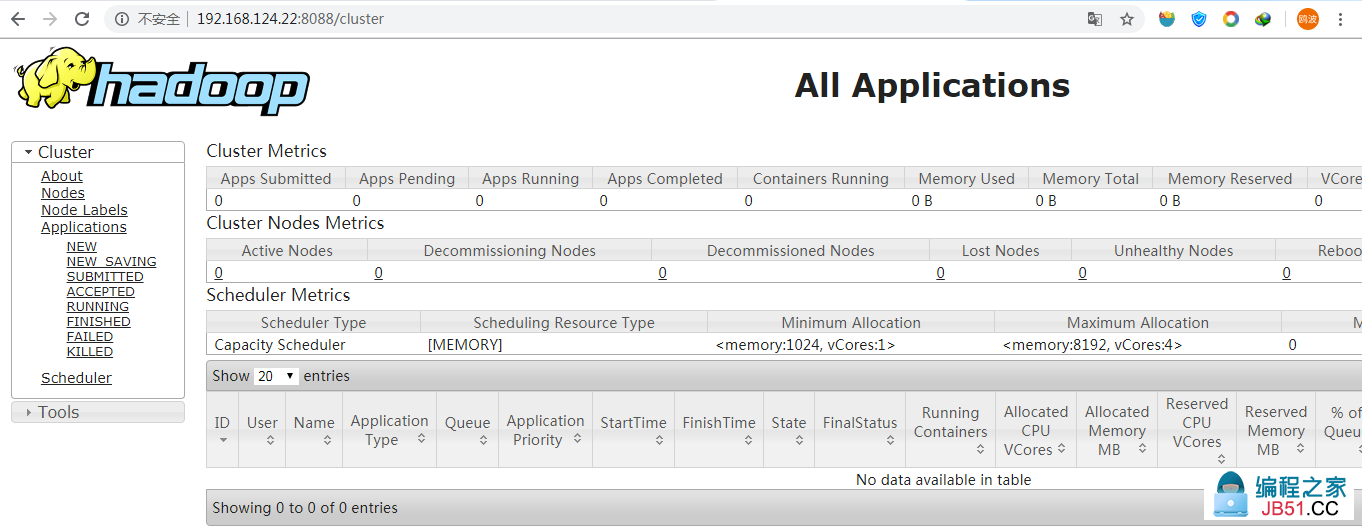
(4)执行WordCount
之前操作参考:https://www.cnblogs.com/xiximayou/p/12389363.html
bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.9.2.jar wordcount /user/gong/input /user/gong/output
然后就可以看到:
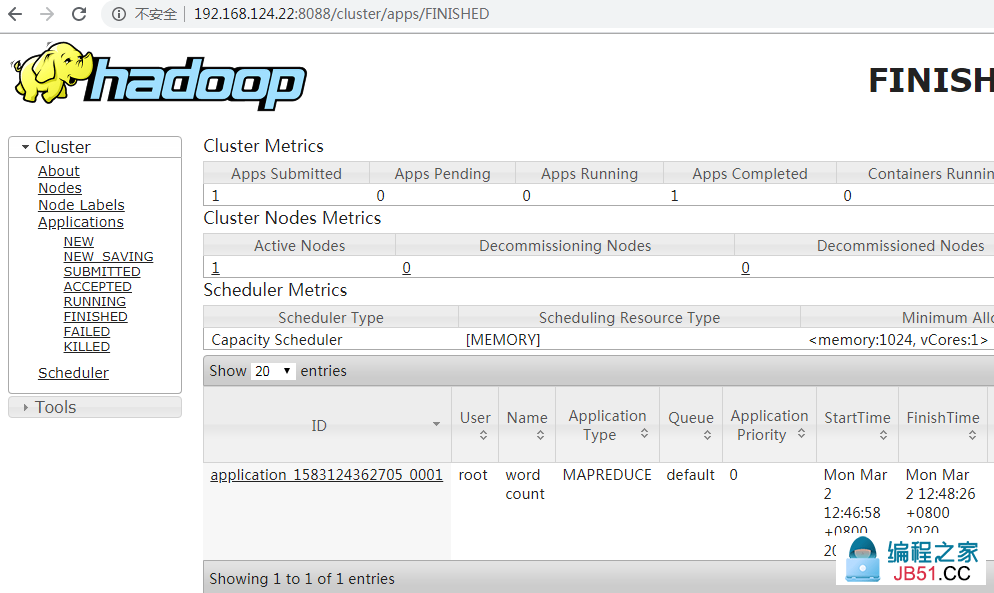
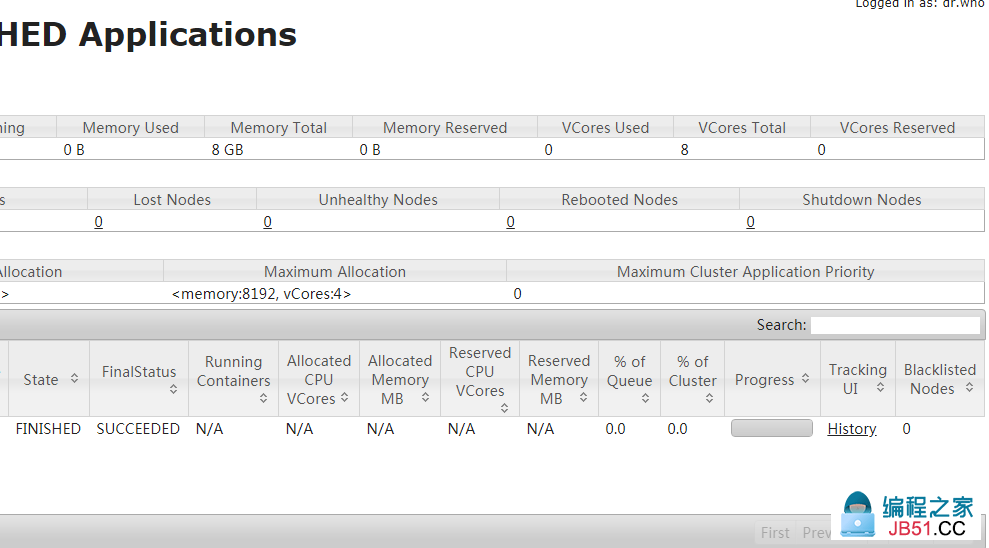
在控制台:

在50070端口:
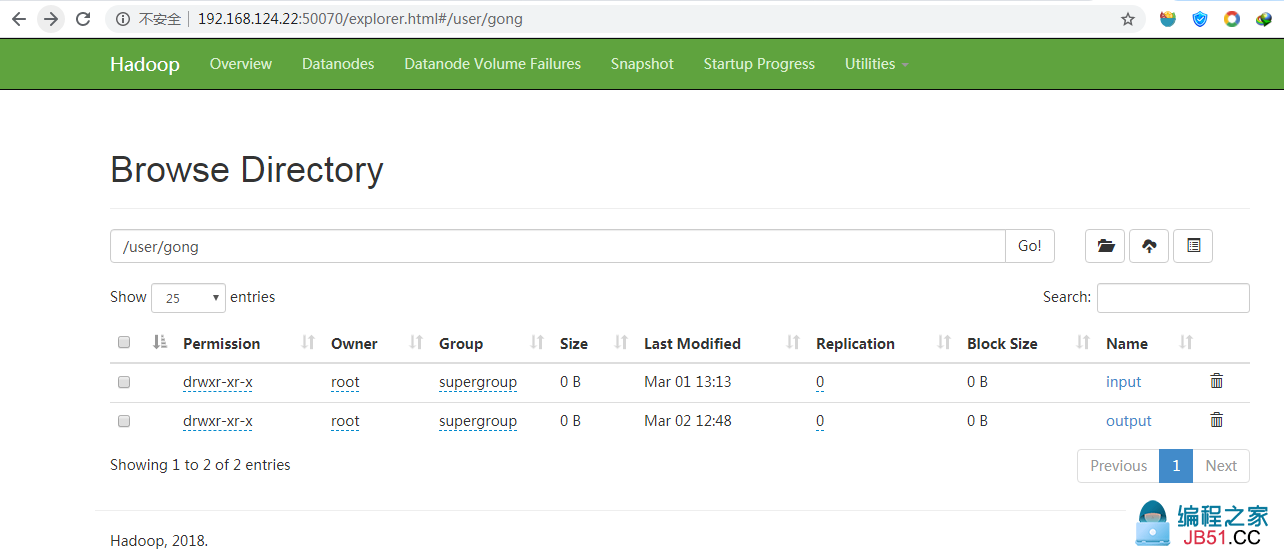
删除应用:sh yarn application -kill jobId
原文链接:/hadoop/991119.html