一、基础环境
现在我们有两台虚拟机了,再克隆两台:

克隆好之后需要做三件事:1、更改主机名称 2、修改ip地址 3、将ip地址和对应的主机号加入到/etc/hosts文件中
1、永久修改主机名
hostnamectl set-hostname hadoop03 等等
2、修改ip地址
vim /etc/sysconfig/network-scripts/ifcfg-ens33
删除掉UUID,然后注意红色框中的

3、将ip地址和主机名加入到/etc/hosts中
vim /etc/hosts

(图中最后应该是hadoop04)
同理对于hadoop04也这么做。hadoop02是我之前学习伪分布式时已经克隆配置好了的。也要在hadoop01和hadoop02中将这四个也添加上去。hadoop01是克隆源,里面的UUID不可删去。
二、集群配置
1、集群部署规划
| hadoop02 | hadoop03 | hadoop04 | |
| HDFS |
NameNode Datanode |
Datanode |
SecondaryNameNode Datanode |
| YARN | NodeManager |
ResourceManager NodeManager |
NodeManager |
说明:NameNode和SecondaryNameNode要求不在一个节点上。ResourceManager不能和NameNode、SecondaryNameNode在同一个节点上。
2、修改hadoop02中的配置
在hadoop-2.9.2目录下:vim etc/hadoop/core-site.xml
<!--指定HDFS中NameNode的地址--> <property> name>fs.defaultFS</value>hdfs://hadoop02:9000> 指定hadoop运行时产生文件的存储目录>hadoop.tmp.dir>/opt/module/hadoop-2.9.2/data/tmp>
在vim etc/hadoop/hadoop-env.sh中配置JAVA_HOME路径
在vim etc/hadoop/hdfs-site.xml中
configuration>
<!--备份的个数--> >dfs.replication>3> >
<!--辅助节点的位置--> >dfs.namenode.secondary.http-address>hadoop04:50090>
在vim etc/hadoop/yarn-env.sh中配置JAVA_HOME路径
在vim etc/hadoop/yarn-site.xml中配置
Reducer获取数据的方式--> >yarn.nodemanager.aux-services>mapreduce_shuffle指定yarn的ResourceManager的地址>yarn.resourcemanager.hostname>hadoop03>
在vim etc/hadoop/mapred-env.sh中配置JAVA_HOME路径
vim etc/hadoop/mapred-site.xml中配置
指定MR运行在yarn上>mapreduce.framework.name>yarn>
3、配置好hadoop02,利用之前博客中的集群分发脚本将配置文件传给hadoop03、hadoop04
xsync.sh /opt/module/hadoop-2.9.2/etc/hadoop/
然后去hadoop03和hadoop04中查看是否成功:
4、在hadoop02、hadoop03、hadoop04中删除掉之前运行的data和logs文件夹,在/opt/modul/hadoop-2.9.2/下
rm -rf data logs
5、集群节点启动
可使用jps指令查看节点是否启动。
(1)在hadoop02中:
首先格式化namenode:bin/hdfs namenode -format
sbin/hadoop-daemon.sh start namenode
sbin/hadoop-daemon.sh start datanode
(2) 在hadoop03中:
sbin/hadoop-daemon.sh start datanode
(3)在hadoop04中:
sbin/hadoop-daemon.sh start datanode
(4)关闭hadoop02中的防火墙
三、查看
在windows中输入http://192.168.124.23:50070/,若出现以下界面:

四、ssh无密码登录
问题:我们都是一个个去别的虚拟机启动节点,当节点很多时,我们要一个个去输入?
事实上,在当前虚拟机中终端中输入:ssh 主机名就可以登录到其他虚拟机
比如,当前的是hadoop02,那么输入ssh hadoop03,就可以登录到hadoop03,只不过每次切换的时候都需要输入密码。为了避免麻烦,可以部署免密登录,只需要输入一次密码,之后再次登录就不需要密码了。那么如何进行操作呢?
免密登录原理:

先来到hadoop02: 输入ls -al查看隐藏的文件,有一个.ssh。cd .ssh

里面有你访问过的主机名称。
生成相应的密钥:ssh-keygen -t rsa
然后输入三次回车。

id_rsa就是私钥,id_rsa.pub就是公钥
将id_rsa.pub中的内容拷贝到hadoop03和hadoop04中:
在hadoop02的.ssh目录下输入:
ssh-copy-id hadoop03
ssh-copy-id hadoop04
然后我们再输入ssh hadoop03
发现就不需要再输入密码了,并且在.ssh目录下会生成一个authorized_keys:里面存放的就是hadoop02的公钥

同时也需要在hadoop02中的.ssh目录下:
ssh-copy-id hadoop02,
也要将root用户配置ssh免密登录:su切换到root,然后执行以上操作
同样对hadoop03和hadoop04重复上述的操作 。
五、群起集群
1、配置slaves
在hadoop02中
vim /opt/module/hadoop-2.9.2/etc/hadoop/slaves
在该文件中加入以下内容(将原本的localhost删除掉):主要是datanode,hadoop02、hadoop03、hadoop04上面都有
hadoop02
hadoop03
hadoop04
注意末尾不能有空格、回车。
然后使用集群分发脚本将其分发给hadoop03、hadoop04
在/opt/module/hadoop-2.9.2/etc/hadoop目录下输入:xsync.sh slaves
接下来将之前启动的那些节点都给停止掉:
sbin/hadoop-daemon.sh stop namenode
sbin/hadoop-daemon.sh stop datanode
然后在hadoop02中的/opt/module/hadoop-2.9.2目录下输入:sbin/start-dfs.sh

诸葛检查一下吧,首先是hadoop02:
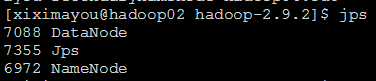
hadoop03:

hadoop04:

说明是成功的,不容易啊。
六、启动yarn
这里注意,我们要在hadoop03中启动。即如果NameNode和ResourceManager不在同一台机器上,要在ResourceManager机器上启动yarn
输入:sbin/start-yarn.sh

可能会报权限不够问题。
那就改权限吧:需要注意看清前面是哪个服务器有权限问题
sudo chmod 777 /tmp/yarn-xiximayou-resourcemanager.pid
sudo chmod 777 /tmp/yarn-xiximayou-nodemanager.pid
之后再执行:

查看一下:
hadoop03:
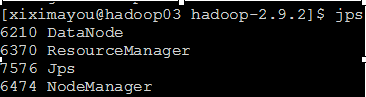
hadoop02:

hadoop04:
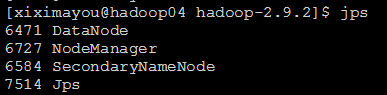
跟预期的对照一下:

七、进行测试
记得将hadoop03和hadoop04的防火墙也给关闭掉
在hadoop02中的hadoop-2.9.2目录下:
bin/hdfs dfs -put wcinput/wc.input /
bin/hdfs dfs -put /opt/software/Market.zip /
然后我们去查看
@H_981_502@
点开Market.zip

大文件(超过128M)分成了两块 ,同时在hadoop02、03、04上都有一份备份。
八、集群停止
sbin/stop-yarn.sh
sbin/stop-dfs.sh
原文链接:/hadoop/991109.html