前面的文章我们知道,libra会把所有的数据都存储在账本中。为了方便业务逻辑和数据的校验,这个存储是以特定的数据结构来实现的,这里我们叫做验证的数据结构。
验证的数据结构是通过Merkle树来实现的。如果大家熟悉其他的区块链的话,大家可能知道Merkle树由于其特殊的结构,被用在大多数区块链中。
下面我们来分别讨论。
存储的数据结构
如下图所示,我们来详细的讲解其存储的数据结构:
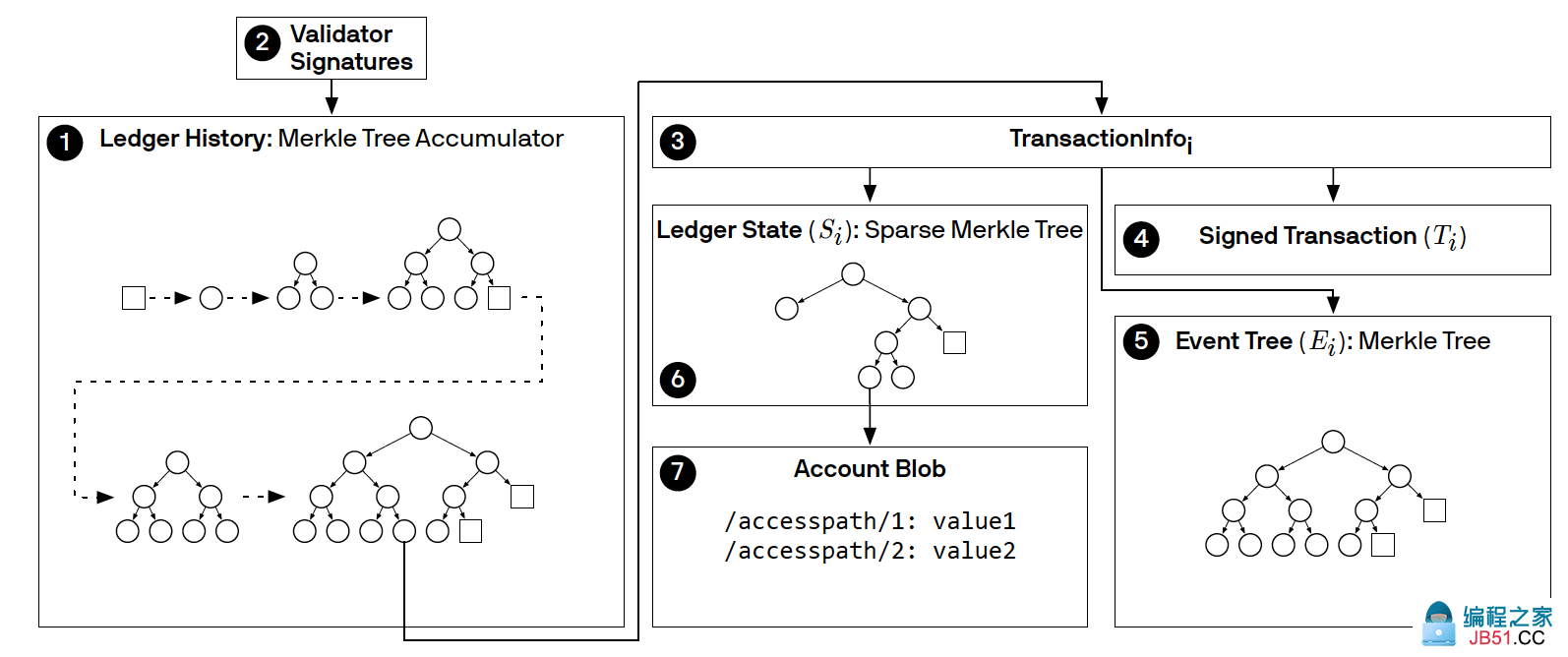
(1)用Merkle树来表示的不断累加的账本历史。而Merkle树的根hash值是通过(2)验证者的签名来得到的。
每当有交易提交到账本的时候,会把TransactionInfo提交到Merkle树的叶子节点。
3表示的就是和这个叶子节点,它包含3部分内容:
- 签名过的交易(4)。
- 交易过程中的事件Event(5),也是以Merkle树来表示。
- 还有交易i执行过后的账本状态(6),是用Sparse Merkle树来表示的,其中它的叶子节点是账户信息。
账本历史
对于大多数区块链来说,比如比特币,他们存储的是交易记录,然后以一个一个包含交易的块来构成的。后面的块包含了前面块的hash值。
这样做的缺点就是,如果我知道某个区块B1是准确的,那么我想验证现在的区块B2,则必须拉取从B1到B2之间的所有交易记录,这对于区块链的验证效率是不高的。
在Libra中,这个得到了改善。我们使用的是单一的Merkle树来提供表示账本历史的验证过的数据结构。
在上面的图中我们可以看到,TransactionInfo包含了账本状态,事件和账户信息。在Merkle树中,每个TransactionInfo都是与一个数据库版本号i相对应的。
在Libra中,我们使用增量的Merkle tree数据结构,这对于构建效率非常有帮助,因为我们只需要向老的Merkle tree中添加新的交易即可。
对于验证节点来说,新的交易只跟上一个账本状态相关,那么验证节点其实可以删除掉不需要的账本状态版本来节省空间和效率。
账本状态
账本状态Si表示了所有在版本i中的账户的信息。它可以看成是一个key value的map。其中key是256bit的账户地址,value就是验证过的账户。
Si也是用Merkle tree来表示的,既然key是256bit,那么整个Merkle tree可以表示为一个2256大小的树如下所示:

如果直接用256大小来表示太浪费空间了,因为我们并没有这么多的账户。那么我们可以做适当的优化:
(1)表示的是原始状态的Merkle tree。
在(2)中,我们将所有的空节点用方框表示。这样会导致树的不平衡,因为叶子节点总是树的最低一层。那么我们可以做适当的优化如(3)所示。
当状态树进行更新的时候,可以重用之前未更新的账户数据,这样可以在验证者中存储状态树的多个版本,也可以加快验证节点的验证速度。
账户
在逻辑上,一个账户是资源和module的集合,并存储在账户的地址中。
在物理上,账户存储的是排序后的access paths映射。access paths可以看成类似文件路径一样的东西。
和其他的区块链不同的是,在Libra中,我们鼓励用户将资源存储在自己的账户中,在现有的版本中,我们对小账户做了优化,在后面的版本中我们同样会对大账户也进行优化升级。
如果所有的资源都存储在账户中,那么随着时间的推移,账户信息会变得越来越大,这会是一个问题。
针对这个问题,Libra提出了空间租赁的概念。简单讲就是给账户一个过期时间,过期之后账户就不可以被访问了。当然,Libra也提供了过期账户的恢复机制,只需要支付一定数量的Libra币即可。
事件
和账户一样,事件也是使用Merkle tree来存储的,并被包含在TransactionInfo中。
更多教程请参考 flydean的博客
原文链接:/Blockchain/993572.html