矩阵在计算机图形学、工程计算中占有举足轻重的地位。在数据结构中考虑的是如何用最小的内存空间来存储同样的一组数据。所以,我们不研究矩阵及其运算等,而把精力放在如何将矩阵更有效地存储在内存中,并能方便地提取矩阵中的元素。
-
数组的存储结构
一个数组的所有元素在内存中占用一段连续的存储空间。
- 以行优先方式存储
- 以列优先方式存储
数组 A[0..5,0..6]的每个元素占五个字节,将其按列优先次序存储在起始地址为 1000 的内存单元中,则元素 A[5,5]的地址是( A )。
A. 1175 B. 1180 C. 1205 D. 1210
-
需要注意的是,当求出数组A[0,0]到特定元素A[5,5]的那部分时,不要着急着写出地址。
因为我们所求出来的所占空间,是A[0,0]的首地址从1开始数(或者说 从A[0,0]的首地址开始到A[5,5]的尾地址(即A[6,1]的首地址))计算时的元素个数6*6=36(即 从A[0,0]到A[5,5],包含A[5,5]有36个元素,但是题目的起始地址一般为0。
所以应该A[0,0]的首地址从0开始数(或者说 从A[0,5]的首地址)计算的话,则是36-1=35(即 从A[0,5],不包含A[5,5]有35个元素)。例如,首地址从0开始数,即意味着当首地址为5时,只存了一个元素的空间,但是地址却是第二个元素的(首)地址。
1 抽象数据类型数组的说明
2 数组的物理结构
3 特殊矩阵的压缩存储: 对称矩阵与三对角矩阵的压缩存储
4 稀疏矩阵的压缩存储:三元组顺序表与十字链表
5 稀疏矩阵的运算(转置算法)
6 广义表的概念:概念、物理结构、递归算法
- 计算数组中给顶元素的地址
- 数组的存储方式(按行或按列优先存放)
- 计算给定元素的前面的元素个数s
- 每个元素的存储空间k
- 该元素地址=起始元素地址+s*k
特殊矩阵
特殊矩阵压缩存储后仍然具有随机存储特性。(只用计算公式即可,无需查找时间)
二维数组→线性
注意:(因为一维数组下标是从0开始的,个数要-1,相当于减掉了自身,所以只用计算前面的元素个数,)(如果一位数组从1开始,就不用-1了,那么就不是前面了,就要加上本身aij,计算自身和前面的元素个数)(如果从1开始,那么下面的公式就要+1)
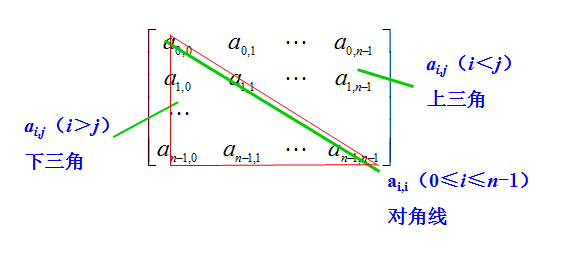
对称矩阵
对称矩阵:矩阵中的元素满足\(a_{i,j}\)=\(a_{j,i}\),另外矩阵必须是方阵。
- 问题:假设有一个n*n的对称矩阵,第一个元素是\(a_{0,0}\),请用一种存储效率较高的存储方式将其存储在一位数组中。
- 解答:将对称矩阵A[0...n-1,0...n-1],存放在一维数据B[n(n+1)/2]中,即 元素\(a_{i,j}\)存放在\(b_k\)中。(只存放主对角线和下三角区的元素)

注意:(因为一维数组下标是从0开始的,个数要-1,相当于减掉了自身,所以只用计算前面的元素个数,)(如果一位数组从1开始,就不用-1了,那么就不是前面了,就要加上本身aij,计算自身和前面的元素个数)
- 在数组B中(下标从0开始),位于\(a_{i,j}\)(i≥j)前面的元素个数为:
- 第0行:1个元素
- 第1行:2个元素
- ...
-
第i-1行:i个元素
注意:0到i-1是等差序列(都是完整的)
- 第i行(不完整):j个元素
- 共计i(i+1)/2+j个元素
-
元素下标k与(i,j)之间的对应关系如下:
\[k=\begin{cases} {{i(i+1)}\over{2}}+j & \text{i≥j,下三角区及对角线}\\ {{j(j+1)}\over{2}}+i & \text{i<j,上三角区}\\ \end{cases}\]
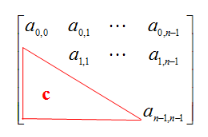
上三角矩阵
其中下三角元素均为常数C或0的n阶矩阵称为上三角矩阵。
- 问题:假设有一个n*n的上三角矩阵,第一个元素是\(a_{0,0...n-1],存放在一位数据B[n(n+1)/2]中,即 元素\(a_{i,j}\)存放在b_k中。(只存放主对角线和下三角区的元素)

- 在数组B中(下标从0开始),位于\(a_{i,j}\)(i≥j)前面的元素个数为:
- 第0行:n个元素
- 第1行:n-1个元素
- ...
-
第i-1行:n-(i-1)=n-i+1个元素
注意:0到i-1是等差序列(都是完整的)
-
第i行(不完整):(n-i)-(n-j)=j-i个元素
注意:n-i为第i行总元素,n-j为j及j后面的元素个数,相减则为j前面的元素个数
- 共计i(2n-i+1)/2+j-i个元素
-
元素下标k与(i,j)之间的对应关系如下:
\[k=\begin{cases} {{i(2n-i+1)}\over{2}}+j-i & \text{i≤j,上三角区及对角线}\\ {{n(n+1)}\over{2}} & \text{i>j,下三角区(存放常量C)(放在最后一个位置)}\\ \end{cases}\]
下三角矩阵
其中上三角元素均为常数C或0的n阶矩阵称为下三角矩阵。
- 问题:假设有一个n*n的下三角矩阵,第一个元素是\(a_{0,j}\)存放在\(b_k\)中。(只存放主对角线和下三角区的元素)
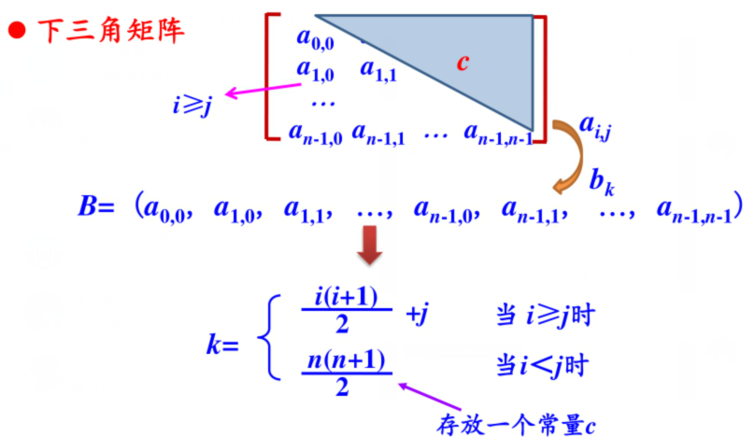

- 在数组B中(下标从0开始),位于\(a_{i,j}\)(i≥j)前面的元素个数为:
- 第0行:1个元素
- 第1行:2个元素
- ...
- 第i-1行(0到i-1是等差序列):i个元素
- 第i行(不完整):j个元素
- 共计i(2n-i+1)/2+j-i个元素
- 元素下标k与(i,下三角区及对角线}\\ {{n(n+1)}\over{2}} & \text{i<j,上三角区(存放常量C)(放在最后一个位置)}\\ \end{cases}\]
对角矩阵
对角矩阵:也称带状矩阵,它的所有非零元素都集中在以主对角线为中心的两侧的带状区域内(对角线的个数为奇数)。换句话说,除了主对角线和主对角线两边的对角线外,其他元素的值均为0。
问题:对于一个按照行优先存储的三对角矩阵,求出第i行带状区域内第一个元素X在一维数组中的下标
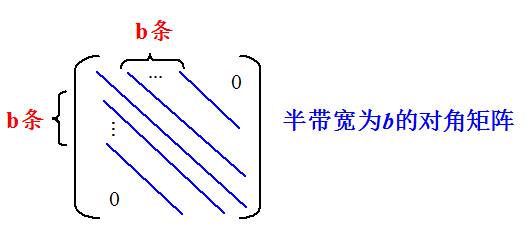
当b=1时,称为三对角矩阵,其压缩地址计算公式如下:\[k=2i+j\]
稀疏矩阵
稀疏矩阵:如果\(A_{m*n}\)中非零元素的个数远远小于总元素的个数,则这个矩阵可以被称为是稀疏矩阵。
稀疏矩阵压缩存储后并不具有随机存储特性。(使用顺序或者链式存储,需要查找时间)
-
稀疏矩阵的压缩存储方法是只存储非0元素。
顺序存储
三元组表示法
-
稀疏矩阵中的每一个非0元素需由一个三元组(i,j,value)唯一确定。(约定非零元素通常以行序为主序顺序排列)
其中,i表示行,j表示列,value表示元素值。
typedef struct {
float val;
int i;
int j;
}Trimat; //三元组结构体
Trimat trimat[maxSize+1];伪地址表示法
-
伪地址是指该元素在矩阵中(包括0元素在内)按照行优先顺序的相对位置,用(value,location)的形式进行存储。
其中,value表示矩阵的具体数值,loaction表示其伪地址值。
伪地址/列数=行号,伪地址%列数=列号
链式存储
邻接表表示法
- 邻接表表示法:创建一个一维数组,数组的下标与矩阵的行号相对应,而数组中的每个元素是一个指针。指针指向一个存储了相应行元素信息的线性表,其中的信息包括元素值,元素列号以及下一个元素的指针。
十字链表表示法
- 每行的所有结点链起来构成一个带行头结点的循环单链表。以hi作为第i行的头结点。
- 每列的所有结点链起来构成一个带列头结点的循环单链表。以hi作为第i列的头结点。
- 行列头结点可以共享。
- 行列头结点个数=MAX(m,n)
增加一个总头结点,并把所有行、列头结点链起来构成一个循环单链表。
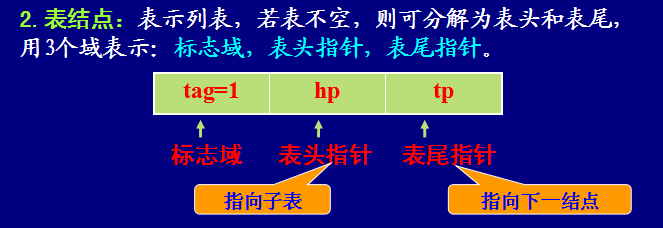
十字链表表示法:每个十字链表都有一个头结点,头结点共有五个域,分别是矩阵的行数、列数、非0元素的个数、矩阵元素的行数组以及矩阵元素的列数组。两个数组都存储了指向矩阵中非零元素的指针。
在十字链表中,为每个非0元素申请一个元素结点,结点包括五个域,分别是行号、列号、元素值、指向同一行下个元素的指针以及指向同一列下个元素的指针。
矩阵转置
矩阵转置:把原本第i行第j列的元素存储在新矩阵中第j行第i列的位置。
广义表
广义表(Lists,又称列表)是线性表的推广。线性表定义为n≥0个元素a0,a1,...,an的有限序列。线性表的元素仅限于原子项,院子是作为结构上不可分割的成分,它可以是一个数或一个结构,若放松对表元素的这种限制,容许它们具有自身结构,这样就产生了广义表的概念。
- 可共享:一个广义表的子表可以是其他已经被定义的广义表的引用,可以为其他广义表所共享。
- 可递归:一个广义表可以是递归定义的,自己可以作为自己的子表。
- 广义表的长度:为表中最上层元素的个数
- 广义表的深度:为表中括号的最大层数,求深度时可以将子表全部展开。
- 广义表的表头(Head)和表尾(Tail):当广义表非空时,第一个元素为广义表的表头,其余元素组成的表是广义表的表尾。
操作
根据表头、表尾的定义可知:任何一个非空广义表的表头是表中第一个元素,它可以是原子,也可以是子表,而其表尾必定是子表。
也就是说,广义表的head操作,取出的元素是什么,那么结果就是什么。但是tail操作取出的元素外必须加一个表——“()”
- 取表头:原子或子表,即 第一个元素(可能是原子或列表)
- 取表尾:(子表集),即 其余元素组成的表(一定是列表)
- 当只有一个元素时,表头当然存在,但是表尾为“()”空(因为没有其余的元素)
举一个简单的列子:已知广义表LS=((a,b,c),(d,e,f)),如果需要取出这个e这个元素,那么使用tail和head如何将这个取出来。
利用上面说的,tail取出来的始终是一个表,即使只有一个简单的一个元素,tail取出来的也是一个表,而head取出来的可以是一个元素也可以是一个表。
解:
tail(LS) = ((d,f))
head(tail(LS)) = (d,f)
tail(head(tail(LS))) = (e,f) //无论如何都会加上这个()括号
head(tail(head(tail(LS)))) = e //head可以去除单个元素
头尾链表存储结构