<atomic>
C++11提供了一个原子类型std::atomic
原子类型只支持bool、char、int、long、指针等整型类型作为模板参数(不支持浮点类型和复合类型)。
原子操作的概念
在原子操作过程中,线程不会发生调度。原子操作是一种不可中断的操作,一旦开始执行,就会一直运行到结束,不会被其他线程打断。因此,在原子操作期间,操作系统的线程调度器不会将cpu分配给其他线程,以确保原子操作的完整性和正确性。
CAS实现原理
CAS(Compare-And-Swap 或 Compare-And-Set)是一种原子操作,用于实现多线程编程中的同步机制。它的基本原理是通过比较和交换来确保一个变量在多个线程访问时的正确性。CAS是许多并发数据结构和算法的基础,比如无锁队列、无锁栈等。
CAS操作的伪代码:
硬件提供的原子性支持,如汇编lock指令等 //整个代码执行都是不可中断的(不是串行)
(asm::lock:)
bool compare_and_swap(int* addr,int expected,int new_value) {
int current = *addr; // 读取当前值
if (current == expected) { //比较当前值和预期值
*addr = new_value; // 如果当前值等于预期值,则更新
return true;
}
return false; // 否则,不更新
}
(asm::unlock:)
使用CAS完成变量的原子操作:
// 共享的整数变量
int shared_var = 10; //ABA问题:无法得知shared_var的全程状态.被修改去又修改回,起止状态不变,过程改变,状态在过程中发生改变CAS却误以为没有改变过.可能导致发生一些隐晦的错误.
//避免ABA,有做变量版本号机制(tag,flag等),或更复杂的实现. -- 有的说回退机制可以:不可以,单单回退机制无法解决ABA问题
void thread_function() {
int expected_value = 10; // 希望 shared_var 的当前值是一般是shared_var的原始值,即10
int new_value = 20; // 目的 将shared_var 更新为 20
// 使用 CAS 操作来原子地更新 shared_var
bool success = compare_and_swap(&shared_var,expected_value,new_value);
if (success) {
// CAS 操作成功
// 这里可以继续处理其他逻辑
} else {
// CAS 操作失败,shared_var 的值不是我们预期的 expected_value
// 可能需要重试或处理其他情况
}
}
CAS 操作的保证
尽管可能会发生 cpu 上下文切换,但 CAS 操作的保证在于其执行过程中的不可中断性。即使发生了 cpu 上下文切换,操作系统和处理器会保证 CAS 操作的执行过程是原子的,其他线程或处理器无法在 CAS 操作期间对其操作的内存位置进行修改。
(CAS == 逻辑检查变量状态+硬件支持语句原子性)
lock和锁的概念
汇编中的
lock指令前缀和编程中的锁(如互斥锁)虽然在概念上都涉及到同步和确保操作的原子性,但它们是不同的东西,作用机制和应用场景也不同。
atomic模板类
构造函数
atomic() noexcept = default;
constexpr atomic( T desired ) noexcept;
atomic( const atomic& ) = delete; //禁止拷贝
desired:用以初始化的值
空对象初始化方式:
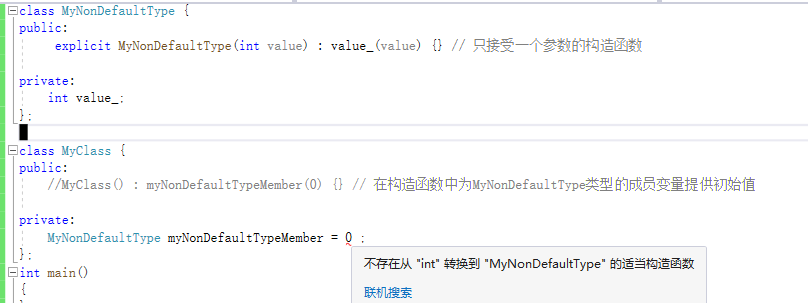
MSVC中类成员atomic类型允许带有缺省值(MSVC优化).但这不是标准C++行为.atomic类型的成员只能在构造函数中完成初始化.
而GCC中不允许使用缺省值,是由编译器实现的.
如果我们要自己实现一个不允许使用缺省值的类型,则可以显式定义构造函数+explicit
公共成员函数:
- operator=
//模拟原生变量的行为,赋值给原生变量
T operator=( T desired ) noexcept;
T operator=( T desired ) volatile noexcept;
//禁止拷贝赋值重载
atomic& operator=( const atomic& ) = delete;
atomic& operator=( const atomic& ) volatile = delete;
- store
和operator=功能一样,将数据存储到原生变量中,没有返回值
void store( T desired,std::memory_order order = std::memory_order_seq_cst ) noexcept;
void store( T desired,std::memory_order order = std::memory_order_seq_cst ) volatile noexcept;
desired:存储到原子变量中的值
order :程序代码内存执行顺序约束(跨平台使用)
- load
取出原生变量的值.
T load( std::memory_order order = std::memory_order_seq_cst ) const noexcept;
T load( std::memory_order order = std::memory_order_seq_cst ) const volatile noexcept;
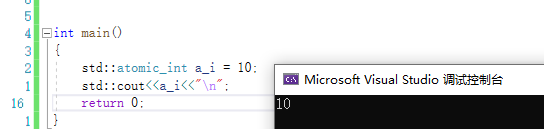
- operator T()
operator T() const volatile noexcept;
operator T() const noexcept;
类类型转换运算符重载.将原子变量类型转化成T类型.
意思是,通过原子变量得到的值就是T类型的值,即得到原生变量的值.等同于load().
示例:
- exchange
T exchange (T val,memory_order sync = memory_order_seq_cst) volatile noexcept;
T exchange (T val,memory_order sync = memory_order_seq_cst) noexcept;
和store()功能类似,将数据存储/覆盖到原生变量中.
不同的功能是,exchange还会返回被覆盖的旧数据.
- compare_exchange_weak & compare_exchange_strong
使用C++11原子量实现自旋锁 - 兔晓侠 - 博客园 (cnblogs.com)
compare_exchange_weak 与 compare_exchange_strong 主要的区别在于内存中的值与expected相等的时候,CAS操作是否一定能成功.
compare_exchange_weak有概率会返回失败,而compare_exchange_strong则一定会成功。
因此,compare_exchange_weak必须与循环搭配使用来保证在失败的时候重试CAS操作。得到的好处是在某些平台上compare_exchange_weak性能更好。按照上面的模型,我们本来就要和while搭配使用,可以使用compare_exchange_weak。
最后内存序的选择没有特殊需求直接使用默认的std::memory_order_seq_cst。
atomic - C++ Reference (cplusplus.com)
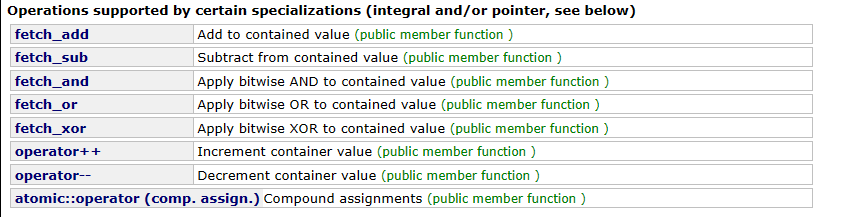
分别是 加、减、按位与、按位或、按位异或、自增、自减、赋值类 操作。
各个 operator 对应的 fetch_ 操作表
| 操作符 | 操作符重载函数 | 等级的成员函数 | 整形 | 指针 | 其他 |
|---|---|---|---|---|---|
| + | atomic::operator+= | atomic::fetch_add | 是 | 是 | 否 |
| - | atomic::operator-= | atomic::fetch_sub | 是 | 是 | 否 |
| & | atomic::operator&= | atomic::fetch_and | 是 | 否 | 否 |
| | | atomic::operator|= | atomic::fetch_or | 是 | 否 | 否 |
| ^ | atomic::operator^= | atomic::fetch_xor | 是 | 否 | 否 |

- C++11还为常用的atomic提供了别名
std::atomic - cppreference.com
有很多,举例出一部分
| 别名 | 原始类型定义 |
|---|---|
| atomic_bool(C++11) | std::atomic |
| atomic_char(C++11) | std::atomic |
| atomic_schar(C++11) | std::atomic |
| atomic_uchar(C++11) | std::atomic |
| atomic_short(C++11) | std::atomic@H_264_403@@H_543_404@ |
| atomic_ushort(C++11) | std::atomic |
| atomic_int(C++11) | std::atomic |
| atomic_uint(C++11) | std::atomic |
| atomic_long(C++11) | std::atomic |
| atomic_ulong(C++11) | std::atomic |
| atomic_llong(C++11) | std::atomic |
| atomic_ullong(C++11) | std::atomic |
atomic与互斥锁的效率比对
例程:
#include <iostream>
#include <thread>
#include <mutex>
#include <atomic>
#include <functional>
using namespace std;
struct Counter
{
Counter():m_value(0){}
void increment()
{
for (int i = 0; i < 100000000; ++i)
{
lock_guard<mutex> locker(m_mutex);
m_value++;
}
}
void decrement()
{
for (int i = 0; i < 100000000; ++i)
{
lock_guard<mutex> locker(m_mutex);
m_value--;
}
}
int m_value = 0;
//std::atomic<int> m_value ;
mutex m_mutex;
};
int main()
{
Counter c;
auto increment = bind(&Counter::increment,&c);
auto decrement = bind(&Counter::decrement,&c);
thread t1(increment);
thread t2(decrement);
t1.join();
t2.join();
std::cout<<"Counter: "<<c.m_value<<"\n";
return 0;
}
GCC下互斥锁版本耗时:
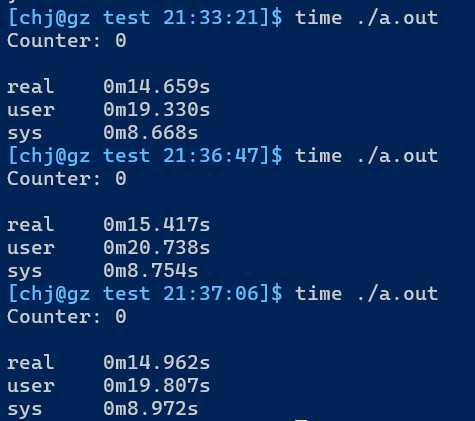
GCC下原子变量版本耗时:
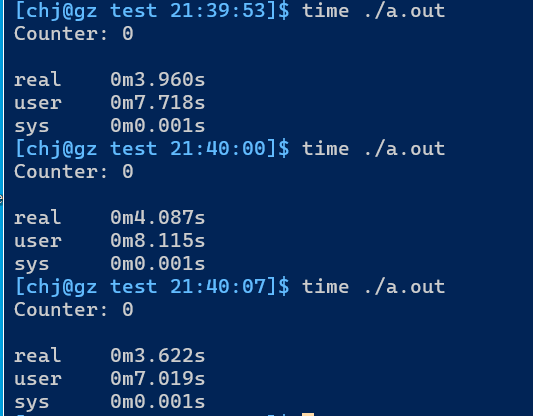
显然,在基本类型线程同步的场景下,原子变量性能更为高效.
原文链接:https://www.cnblogs.com/DSCL-ing/p/18302143